Update-on-self sorting |
|
|
|
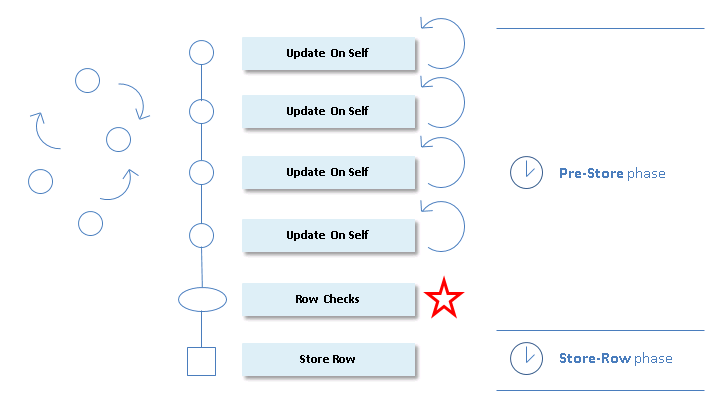
When flat files are created, constraints that potentially give rise to update-on-self corrections are sorted internally. For each constraint, sorting is on the basis of: •How many other constraints each constraint potentially deactivates. This has a higher priority than: •How many other constraints each constraint potentially causes to be evaluated. In other words, for each "update-on-self constraint" that comes into play for a given store-record event, the number of other constraints potentially deactivated by this constraint determines the ranking of the constraint in the execution order. For constraints with the same ranking, those that cause evaluation of most others get the higher ranking. The following picture is an attempt to visualise that "update-on-self constraints" are sorted for optimisation:
You can manually influence this type of optimisation by adding preconditions and postconditions to constraint SQL statements where possible. There is no overhead time for sorting and deactivation strategies because these strategies have been applied when the flat file (the .CON file) was generated.
See also Deactivation between constraints Deactivation between incoming data, preconditions and postconditions |

|